WEKA 大中华区资深技术顾问吴岱侑 Ray Wu 近期在接受 iThome 采访中分享了他对于如何突破大型 AI 数据集 I/O瓶颈的见解。探讨了随着 AI技术的兴起,企业应该选择怎样的方式为非结构化数据及I/O密集型工作负载提供支持。
在过去的一年中,随着ChatGPT、生成式 AI 等技术的风靡,推动了“AI民主化”的浪潮,使得企业对引入 AI 的热情愈发高涨。然而,当许多企业购置了GPU 服务器、100/200/400Gbps的高速网卡(InfiniBand或以太网)、NVMe高速SSD等高级设备,迫不及待地想要借助 AI/ML 技术从海量数据集中披沙拣金。他们却发现 I/O 速度成为了最头疼的问题,数据读写速度过慢导致宝贵的计算资源经常处于闲置状态。
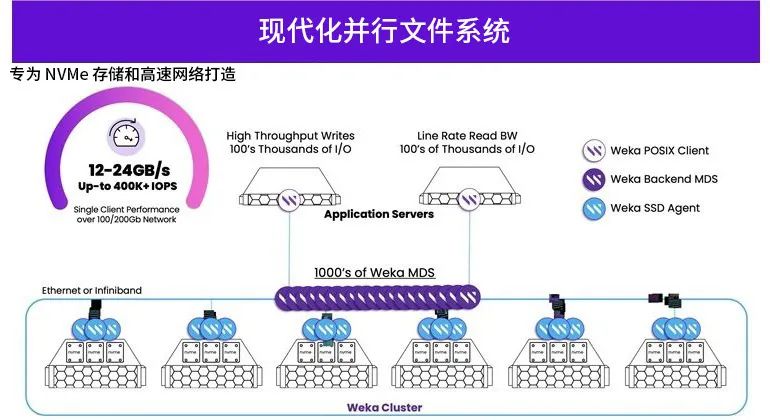
WEKA 大中华区资深技术顾问吴岱侑指出,为了突破 I/O 瓶颈,越来越多企业认识到必须摆脱传统的存储模式,寻找一种能够支持分布式横向扩展(Scale Out)架构,并显著缩短数据读写时间的系统。这促使了并行文件系统(Parallel File System)和软件定义存储(Software Defined Storage;SDS)等技术方案的崛起,成为企业或机构追逐的目标。
WEKA 是基于非结构化数据和IO密集型工作负载而设计的的解决方案,专为数据紧缺的 GPU 提供支持。WEKA® Data Platform 可以在混合多云环境中运行,帮助有 GPU 计算需求的客户,让他们体验到动辄 10 倍、30 倍以上的性能增益。
数据读写性能不佳,导致GPU利用率下降
吴岱侑表示,近年来,GPU、CPU、网络等技术不断精进,基础架构能力显著提高。然而,存储技术的进步相对缓慢,提供的I/O 性能或吞吐量不如预期,导致GPU无法及时获取数据,从而使利用率下降。
他进一步解释,企业在进行 AI/ML 运算前,需要先将数据传输到GPU服务器内部的本地磁盘(NVMe SSD),然后将数据载入GPU内置的“高带宽存储器(HBM)”,才能展开运算。但是,一旦数据集过大,那么从数据的切割、复制到载入高带宽内存的整个过程可能耗费冗长的时间。即使 GPU 算力再强,也只能暂时歇息,花时间等待数据到位。
以近期火爆的ChatGPT、大型语言模型(LLM)来说,它们所需的数据量大约在几十 GB 左右。如果用户懂得妥善分配 GPU 资源,懂得利用分批运算模式,在传统存储架构下或许能勉强应对。但是,如果数据量更大,比如高科技制造业进行瑕疵检测、医疗业进行基因测序、汽车业进行自动驾驶模拟,甚至企业想要利用使用人工智能生成实时或虚拟视频……等等应用场景,仅仅依靠现有的存储设备,恐怕连将数据传送到本地磁盘都将面临困难;一旦善用并行文件系统,就能让众多节点同步进行读写,从而在最短时间内将大量数据传送到 GPU 服务器的本地磁盘。
自动优化助攻,轻松实现IOPS与吞吐量完美均衡
然而此刻问题又来了,并行文件系统并非新产品,早在20、30年前就开始应用于高性能计算(HPC)环境,可以想象当时的功能要求不及现在高,系统架构当然也不会太过复杂。随着环境需求逐渐改变,迫使并行文件系统厂商开始不断地进行功能扩展,陆续新增Samba、NFS、Tape、对象存储等功能,使得架构复杂度急剧提升,同时也增加了维护、管理和调整的难度,给用户带来了巨大困扰。
相较之下,作为后来者的WEKA,则显得更加讨喜。首先,它的架构相对简单,在硬件上简化为标准x86架构,每台服务器的规格都一致,所有功能都以容器化方式融入服务器;管理者只需维护标准硬件,没有额外的管理负担,也便于进行后续的调试或性能调整工作,这些都可能为企业带来巨大效益。
“如今,一个 GPU 渲染农场可能同时运行小文件、大语言模型、语音识别、图像识别等不同类型的应用,每种应用都有截然不同的存储 I/O 类型,传统架构因此难以在不同工作类型进行优化调整,只能做出妥协和取舍,” 吴岱侑表示,传统存储架构通常只能针对单一工作类型进行优化,例如提供高IOPS或高吞吐量,很难同时兼顾多种不同工作类型的性能需求。相比之下,WEKA则不会陷入这种困境,因为其系统架构经过全新设计,能够同时满足不同工作类型的性能需求。比如,有些应用对元数据(Metadata)的访问和查询需求较高,有些则需要频繁导入大量图像或媒体数据。为此,WEKA 专门将元数据和 Data Trunk 分开,并结合自动优化(Auto-tuning)功能,客户无需动手调整,就能够高效流畅地调用大数据或小数据,在IOPS与吞吐量之间实现平衡。
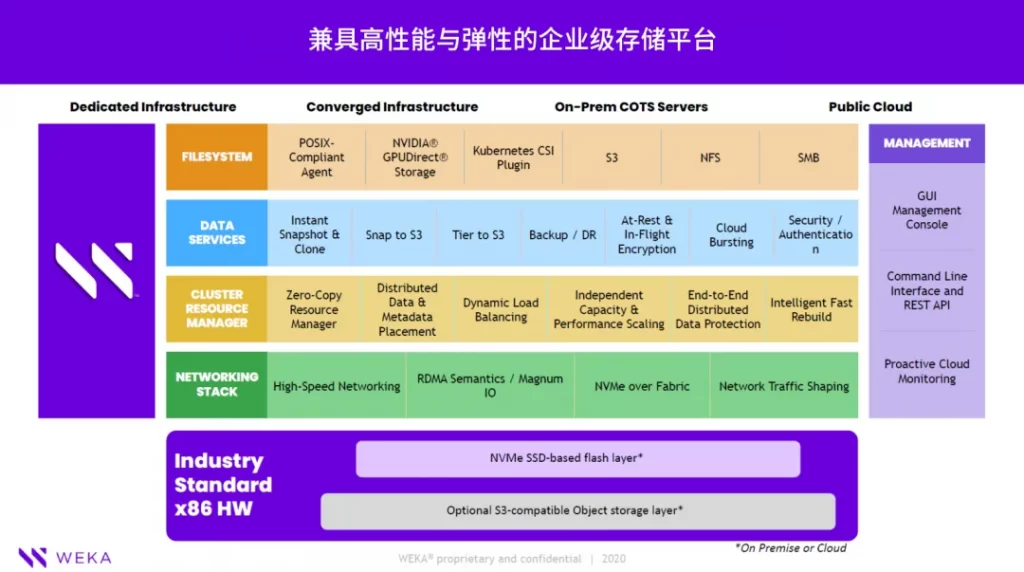
WEKA® Data Platform产品优势
除本身技术优势外,WEKA® Data Platform 还具备许多其他特色。
软件定义存储
WEKA是基于软件的存储,不需要与特定硬件捆绑销售,便于用户自由选择在任何品牌的 x86 服务器上运行WEKA。
专为云而构建
WEKA基于云原生架构,可在本地、云中、边缘和多云混合环境之间无缝运行。
零拷贝多协议就绪
此外WEKA拥有零拷贝(Zero-Copy)优势, 当用户将所有原始数据存入WEKA 后,不同的前端应用可以通过POSIX、GDS、NFS、SMB或S3等多协议直接访问所需数据,在这个过程中完全不需要费时进行数据拷贝。
数据分层存储
用户可将热数据存放在高性能的闪存存储层,将冷数据自动归档于低成本的S3对象存储层,完美兼顾性能与成本需求。
总的来说,WEKA让企业通过标准的x86服务器和经济实惠的对象存储(Object Storage)来构建并行文件系统,进而降低存储建设成本(TCO)、消除特定存储厂商绑定(Vendor lock-in),从而高效地支持各类AI工作负载,并持续利用数据创造商业价值。